While each company’s incident management procedure are similar, there are unique factors to be considered to understand how to create an incident management procedure. We have created this incident management procedure best practices step by step guide to help you build a procedure that works for your team and company. We look forward to your comments and questions.
Incident Management Title and Change History
The incident management procedure title page is pretty straight forward. Include your company name, title of the document, who prepared it, and an original draft date. Your incident management procedure should include a change history section. As you update the incident management procedure, the change history should capture the version number, change author, description of the change, and the date of the change.
Table of Contents
Adding a table of contents to your incident management procedure will make it easy for your reader to quickly find a section. During a critical incident, having a table of contents could save valuable time for your staff.
Incident Management Objectives and Purpose
Stating the objective and purpose of your incident management procedure is important for the reader. An example of a purpose is “Incident management is the process to handle all incidents involving IT Personnel in a consistent, timely, professional, and cost-effective manner.”
Examples of the objective of your incident management procedure could include;
- To resolve an incident as quickly and efficiently as possible
- To ensure client satisfaction with the quality of support
- To provide a consistent and repeatable process for incidents
- Ensure the process is beneficial for Information Technology department, while minimizing the bureaucratic impact on the customer and support communities
- Supply accurate and timely information pertaining to incidents
- To use common process and tools for providing customer support that provides:
- Usability and responsiveness to enable quick call entry
- Measurements to understand workload
- Continuous review and improvement of the current tools and processes
- Links into other defined and approved processes
Incident Management Scope
The scope section lets the reader know what is included and excluded from coverage by this incident management procedure.
Incident Management Business Principles
Business Principles will set your incident management best practices foundational rules for your department. Below are some general incident management best practices.
- Incident Owner – Identifying the incident ticket owner is important to ensure that all activities are occurring in a timely manner. These activities include monitoring, tracking, and communicating status updates to both customers and Help Desk staff. All communication with the customer will be documented into the incident ticket. Typically the Help Desk Agent will be identified as the Incident Owner for all incident tickets they create.
- Incident Tickets – All contacts and interaction with the customer must be documented into an incident ticket. If it is not documented, then it did not happen.
- Incident Priority – The incident priority or severity should be set by using an incident priority matrix. It is important to prioritize incident tickets so normal operations can be restored as quickly as possible in a prioritized fashion with the highest priority incident receiving the most immediate attention.
- New Incidents – If the customer is contacting the Help Desk about a new issue, the Help Desk Agent will create a new incident ticket and will fill out all appropriate ticket fields.
- Existing Incidents – If the customer is contacting the Help Desk about an existing issue, the Help Desk Agent will search for existing tickets and will provide the user with a status update. The incident ticket must be updated with a summary of the interaction.
- Escalation Queue Management – If the Help Desk is unable to resolve an incident, the Help Desk Agent will assign the incident ticket to the appropriate Escalation Queue for the escalated work team. The Manager of the escalation queue to which the incident has been assigned, will ensure the appropriate resources are monitoring the queue for newly assigned incident tickets. A member of the escalation queue will acknowledge the incident ticket and identify himself/herself as the assignee of the incident ticket. If the issue and customer information required to perform the resolution activities are missing, or if it was assigned to the wrong escalation group, the assignee or Escalation Queue manager will assign the ticket back to the Help Desk queue with a documented reason for the reassignment.
- VIP Users – A statement of what agreed additional level of service VIP users will be entitled to.
- Incident resolution – The incident ticket should be resolved when the service has been restored to standard operation, which may be a permanent fix or a temporary workaround. Incidents should not be moved to a status of “resolved” until service has been restored.
- Incident closure – Incidents should not be moved to a status of “closed” until the incident resolution has been confirmed with the customer. The Help Desk should have an incident closure process if the Help Desk Agent is unable to make contact with the customer after multiple attempts. We recommend that the Help Desk staff will attempt to contact the customer three (3) times by two (2) different methods (phone and e-mail) in a minimum five (5) business day period before moving the incident to a “closed” status.
- Incident reopen – An incident in a “closed” status should never be reopened. If the incident was not resolved, a new incident ticket should be opened and it will be related to the previous incident.
- Root cause – All priority 1 or critical incidents should have a problem management investigation ticket opened for a root cause analysis.
Customer Contact Channels
Your incident management procedure should identify all customer contact channels. Customer contact channels are the methods used by the customer to request help or report a service interruption. Examples include phone, email, customer portal, walk up, and chat. System monitoring should also be included if monitoring events automatically create incident tickets.
Incident Prioritization
Due to most Help Desk resource constraints, not all incidents can be worked on simultaneously. Incident tickets will need to be prioritized by incident based on impact and urgency. Incident impact is the potential financial, brand or security damage caused by the incident on the business organization before it can be resolved. Urgency is how quickly incident resolution is required. Below is an incident priority matrix example.
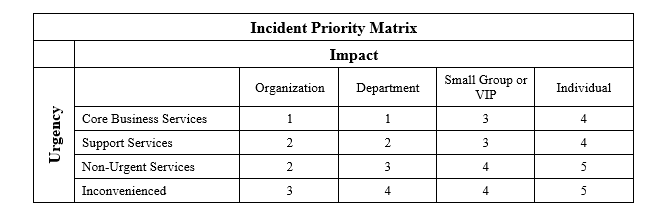
Core Business Service – In the example, a Core Business Service is a defined business system made up of servers, applications, databases, telecommunications, and processes that when degraded or unavailable, will cause a direct financial, brand or security impact on the business organization.
Support Service – In the example, a Support Service is a defined business service that directly supports the execution of a core business service. When a Support Service is degraded or unavailable, operations can continue in a restricted fashion or with a workaround, although long-term productivity might be adversely affected.
Leave a Reply